Today's focus was understanding the RAG pipeline.
RAG can be thought as a two steps process: knowledge base construction and retrieval.
Let's say you have a big document that you want to store in your knowledge base for RAG. You now need to break it into smaller chunks. There's different ways to do this. Fixed-size chunks (~300 tokens in AWS Bedrock) are easy and predictable but ignore natural boundaries and can split important sentences. Semantic chunking instead respects paragraphs and headings so each chunk represents a coherent idea. For deeply structured documents like manuals, hierarchical chunking works best: you preserve chapters/sections and can answer both narrow and broad questions with the right level of context.
Now each chunk is converted to an embedding. Embeddings are fixed-length multi-dimensional vectors that represent the content of each chunk.
Different embedding models create embeddings optimized for specific tasks, such as text similarity, image recognition, or multimodal understanding. These embeddings, along with the original chunk text and other metadata are then stored in a vector database to allow for document retrieval.
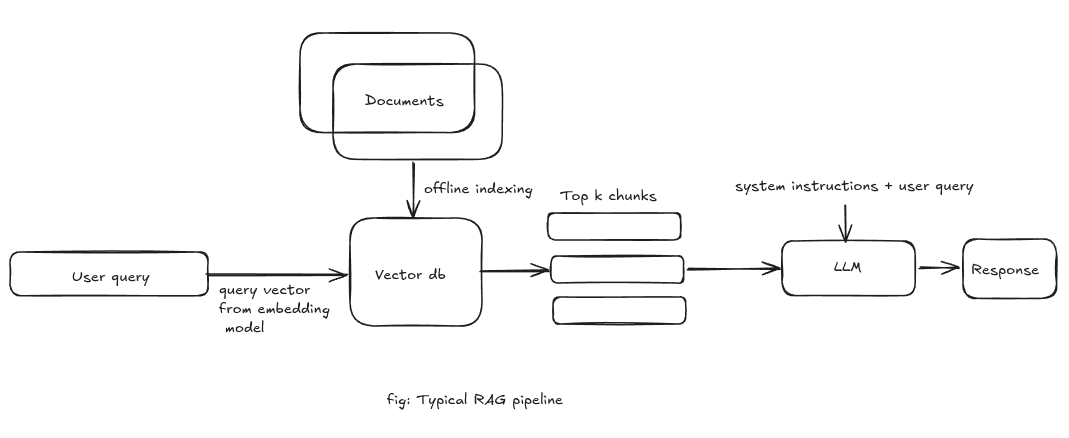
During retrieval, a vector search using a query(which is also converted to an embedding) returns the top-k chunks.
The vector search relies on various distance metrics to determine similarity between embeddings in high-dimensional space. Three common distance metrics are:
- Cosine similarity
- Euclidean distance
- Manhattan distance
- Dot product Cosine similarity is the most commonly used distance metric. It is the cosine of the angle between two vectors so it focuses on the orientation of the vectors rather than their magnitude making it more suitable for text similarity.
Once we have the top-k chunks, those chunks are passed to the LLM as context for the final response.
AWS vector store solutions:
- Bedrock Knowledge Base
- Opensearch
- S3 vector store
- RDS, Aurora, DynamoDB with vector extension
- Specialized vector store solutions from marketplace - like pinecone, qdrant, chroma, etc that you can use inside EC2 instances or use a managed service.
Bedrock knowledge base supports PostgreSQL, OpenSearch, Neptune analytics, Pinecone, Redis Enterprise Cloud.
Bedrock supports both Heirarchical chunking and topic wise chunking(Opensearch and Neural Plugin). In a real-world application, you might want to use a hybrid approach. Topic wise chunking inside each heirarchy.
Updating the knowledge base:
- Use event-driven architecture to update the knowledge base when new content is added. Amazon EventBridge, Amazon S3 event notifications, or database triggers can be used to trigger the update. Handle the updates in a separate a lambda function or step function. To do this, CDC is a good approach. You can create such architecture using Amazon EventBridge, Amazon Simple Queue Service (Amazon SQS), or Amazon Kinesis to route change events to appropriate processing systems.
- Use a scheduled batch job to update the knowledge base periodically.
Vector storage performance considerations:
- Different types of indexing algorithm (HNSW, IVF, LSH)
- Sharding allows vector search implementations to scale horizontally while maintaining fast response times through intelligent data partitioning and query routing mechanisms: can shard based on domain, time/hash/alphabetical etc.
- Embedding model - choose domain specific embedding model if appropriate.
We also need to track the age of embeddings in the vector stores to measure data freshness and identify content that requires updates.
Amazon S3 Vectors:
- Can be multi-region: Automatic replication: Sub-15-minute synchronization across regions
- Can use s3 storage lens for performance insights
- Metadata-based enhancements: Pre-filtering(Reduce search space by 50-70%), Heirarchical Organization(Using logical prefix)
- Query latency(P95): <500ms
Documents metadata considerations:
- Use consistent date format: ISO-8601 formatting and standards for dates and times is a good practice. Store created, updated dates and create temporal queries to retrieve/rank content based on time. Consistent formatting turns on reliable temporal operations and simplifies integration with external systems.
- Designing effective tag structures for domain classification and filtering.
- Use user-defined metadata with x-amz-meta prefix in s3
- s3 meta data availability: 23 regions
If you're storing documents in S3 for AI applications, attach structured metadata so retrieval systems and AI models can filter, rank, and understand documents better.
Enterprise Content integration for Gen AI: Amazon Kendra for indexing and querying: Data sources: Sharepoint, Confluence, File systems, Databases etc.
On the serving side, streaming APIs make chat UIs feel responsive by returning tokens as they're generated, while batch APIs are better for offline and bulk jobs. Within streaming, REST (HTTP chunked/SSE) is simple to integrate, whereas WebSockets give low-latency, bi-directional communication over a long-lived connection.
On AWS, Bedrock on-demand is the easiest way to start and is ideal for spiky or uncertain traffic. Provisioned Throughput reserves capacity and makes sense once you care about strict SLAs or have fine-tuned models.
When you need full control over hardware, networking or open-source models, you can use SageMaker endpoints as Bedrock won't support it.
Model selection and routing
Amazon Nova models cover different trade-offs: Nova 2 Pro for complex reasoning, Nova 2 Lite for fast, cheaper responses, and Nova 2 Sonic for real-time conversation. For deeper customization, Nova Forge or SageMaker's training capabilities can be used to build or fine-tune models, with agent-guided workflows helping choose the right approach.
Routing can be static in code or dynamic. Bedrock prompt routing can automatically direct requests across models within the same family (Anthropic, Amazon, Meta) to balance quality and cost. You can also implement routing in Lambda behind API Gateway or with Step Functions to orchestrate more complex flows.
Serverless AI building blocks and infrastructure
Key serverless components are: Lambda as an abstraction layer, API Gateway as the unified Bedrock interface with auth and monitoring, and AppConfig for dynamic configuration (model choice, routing rules, feature flags). For heavier workloads, AWS offers EC2 GPU instances, AI Factories for on-prem deployment, and SageMaker HyperPod for large-scale training—while still letting you expose models through a serverless, API-led interface in production.